我在使用 golang 时遇到了一个并发设置问题,由于 golang 这两年更新也很快,底层调度器在不断的优化,导致搜索网上资料,有很多已经过时,将资料整理并修正记录一下。
用户线程和内核线程关系
用户空间线程和内核空间线程之间的映射关系有:N:1,1:1 和 M:N。N:1 是指多个(N)用户线程始终在一个内核线程上跑,上下文切换确实很快,但是无法真正的利用多核。1:1 是指 一个用户线程就只在一个内核线程上跑,这时可以利用多核,但是上下文切换很慢。 M:N 是指多个 goroutine 在多个内核线程上跑,这个看似可以集齐上面两者的优势,但是无疑增加了调度的难度。golang 的调度器就是用 M:N 映射关系实现。
golang 中 M:N 的实现
Go 的调度器内部有三个重要的结构:M,P,G。
- M: 代表真正的内核 OS 线程,真正干活的人。
- G: 代表一个 goroutine,它有自己的栈,指令指针和其他信息(正在等待的 channel 等等),用于调度。
- P: 代表调度的上下文,可以把它看做一个局部的调度器,使 Go 代码在一个线程上跑,它是实现从 N:1 到 N:M 映射的关键。
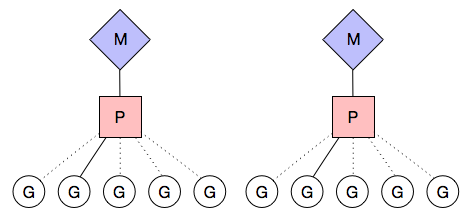
图中看,有 2 个物理线程 M,每一个 M 都拥有一个 context(P),每一个也都有一个正在运行的 goroutine。P 的数量可以通过 GOMAXPROCS() 来设置,它其实也就代表了真正的并发度,即有多少个 goroutine 可以同时运行。
图中虚线连接的那些 goroutine 并没有运行,而是出于 ready 的就绪态,正在等待被调度。P 维护着这个队列(称之为 runqueue ),Go 语言里,启动一个 goroutine 很容易:go function 就行,所以每有一个 go 语句被执行,runqueue 队列就在其末尾加入一个 goroutine,在下一个调度点,就从 runqueue 中取出一个 goroutine 执行。到底是取出哪个 goroutine 来执行,是 golang 的调度器根据各种因素决定的。
ps:在 1.3 版本以前,G 的调度是非抢占式的,只要你的状态共享的代码块不跨越调度点或者 IO 调度点, 是不需要加锁的, 天然的无锁状态。1.3 以后实现了类似抢占式的调度(编译器会在代码中插内容触发调度),上面的天然无锁状态也就不存在了。就算用 GOMAXPROCS 把最大并行数(P)设置为 1, 也无法用无锁的模型玩耍了。
那么如果 G 中执行了带阻塞的系统调用,调度会有什么样的变化呢?如下图所示:
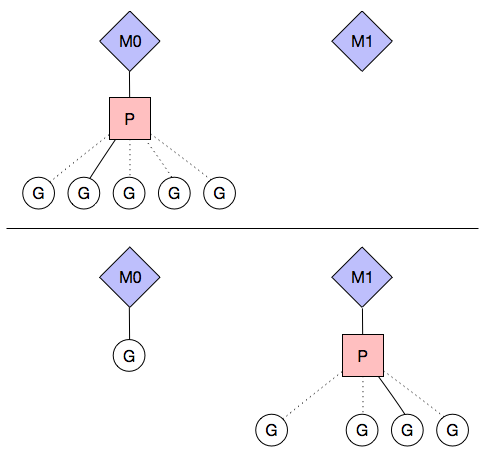
P 转而在 OS 线程 M1 上运行,这样就不会因为一个阻塞调用,而阻塞了 P 上所有的 G。图中的 M1 可能是被创建,或者从线程池中取出。当被丢弃的 M0-G 对完成系统调用变成可执行状态时,它必须尝试取得一个 context P 来运行 goroutine,一般情况下,它会从其他的 OS 线程那里偷一个 P 过来,如果没有偷到的话,它就把 goroutine 放在一个 global runqueue 里,然后自己就去睡大觉了(回到线程池里)。Contexts 们也会周期性的检查 global runqueue,否则 global runqueue 上的 goroutine 永远无法执行。这也就是为什么即使 GOMAXPROCS P 被设置成 1,Goroutine 还是能用到多核处理。
当一个 P 对象将维护的 runqueue 里的 G 全部执行完之后,可以从别的 P 的 runqueue 底部拿到一半的 G 放入自己的 runqueue 中执行,这也就是为什么叫做 Work stealing 算法,这也是 Goroutine 为何高效的一个很大原因。如下图所示:
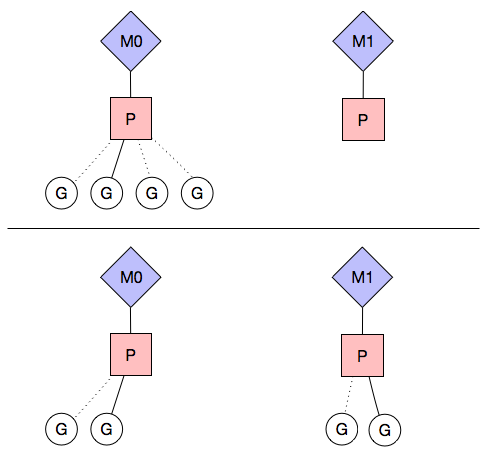
G 比系统线程要简单许多,相对于在内核态进行上下文切换,G 的切换代价低了很多,调度策略非常简单,毕竟操作系统要为各种复杂的场景提供完整的解决方案,而通常我们应用程序层面解决的问题都相对简单。
非阻塞 IO 与 IO 多路复用
现在我们知道协程的创建和上线文切换都非常“轻”,但是在进行带阻塞系统调用时执行体 M 会被阻塞,这就需要创建新的系统资源,而在高并发的 web 场景下如果使用阻塞的 IO 调用,网络 IO 大概率阻塞较长的时间,导致我们还是要创建大量的系统线程,所以 Go 需要尽量使用非阻塞的系统调用,虽然 Go 的标准库提供的是同步阻塞的 IO 模型,但底层其实是使用内核提供的非阻塞的 IO 模型。当 Goroutine 进行 IO 操作而数据未就绪时,syscall 返回 error,当前执行的 Goroutine 被置为阻塞态而 M 并没有被阻塞,P 就可以继续使用当前执行体 M 继续执行下一个 G,这样 P 就不需要再跑到别的 M,从而也就不会去创建新的 M。
当然只有非阻塞 IO 还不够,Go 抽象了 netpoller 对象来进行 IO 多路复用,在 linux 下通过 epoll 来实现 IO 多路复用。当 G 由于 IO 未就绪而被置为阻塞态时,netpoller 将对应的文件描述符注册到 epoll 实例中进行 epoll_wait,就绪的文件描述符回调通知给阻塞的 G,G 更新为就绪状态等待调度继续执行,这种实现使得 Golang 在进行高并发的网络通信时变得非常强大,相比于 php-fpm 的多进程模型,Golang Http Server 使用很少的线程资源运行非常多的 Goroutine,而且尽可能的让每一个线程都忙碌起来,而不是阻塞在 IO 调用上,提高了 CPU 的利用率。
最后
Golang 依靠协程和底层的 IO 多路复用模型,让我们可以简单的通过同步编程的方式来解决高并发的 IO 密集型操作,语言本身工程性也非常强。Golang 基本保持着每半年发布一个正式版本的迭代速度。现在的版本已经是 1.8,GC 的优化也已经非常好了,国内已经有很多公司纷纷采用,相信在未来会越来越好的。
整理资料来源
www.zhihu.com/question/20862617
m.yl1001.com/group_article/3231471449287668.htm